

What Data Science Forgot
Getting back to the roots

Welcome to Polymathic Being, a place to explore counterintuitive insights across multiple domains. These essays take common topics and investigate them from different perspectives and disciplines to come up with unique insights and solutions.
Today's topic tackles my consistent frustrations with the Data Science community and how they apply machine learning algorithms and other tools to data without fully understanding the rest of the context. While this problem isn’t constrained to Data Science specifically, this discipline does lead the pack in examples. To understand this problem we’ll focus on three things that have been forgotten. The first thing forgotten is the history of where Data Science came from and the second two things forgotten derive from the first, and leads to the majority of the issues with applying Data Science solutions.

History and Genealogy of Data Science
I always find it interesting how ideas ebb, flow, morph, merge, and emerge with claims of uniqueness. Data Science is one of those things that broke upon our consciousness in the mid-aughts and hasn’t slowed down yet. But just where did this dynamic and incredibly fast-growing discipline come from and, more importantly, what did they forget about where they came from? Let’s start with a little history.
Operations Research is a scientific discipline of applied math, statistical analysis, and a bevy of additional analytics tools such as modeling and simulation, and wargaming. Its status as a discipline was firmly established in WWII analytics surrounding things like, how to place radars, solving inaccurate anti-aircraft fire, and even where to place armor on bombers for survivability.
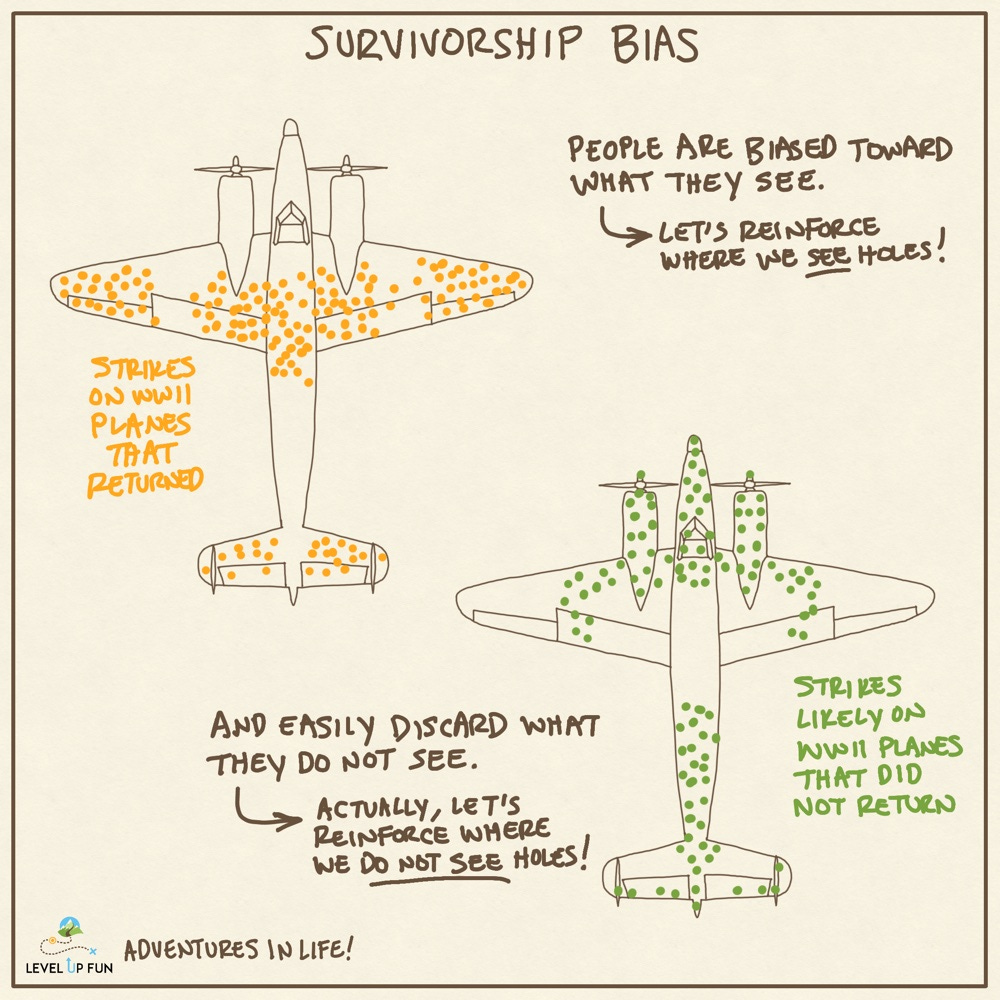
This last one on aircraft survivability is interesting because, when the Mathematician Abraham Wald mapped the distributions of bullet holes, what he postulated, that others weren’t considering, was that these were the planes that survived those holes. It took a divergent thinker to comment that the places where there were no holes on returning planes were more likely where the planes that didn’t come back suffered damage. This is a classic case of reconceptualizing a problem by rethinking the data. But I digress.
Operations Research (OR) was also applied to logistics, manufacturing, troop transportation, and virtually every aspect of process optimization needed for the Allies to win the war. To this day, Operations Research and Systems Analysis (ORSA) is a technical focus area in each branch of the US Military. Professional societies such as the Military Operations Research Society (MORS) and Institute for Operations Research and the Management Sciences (INFORMS) are dedicated to the maturation of this discipline. Albeit slightly niche and esoteric, this profession has had a large impact on the world through multiple, separate vectors.
When WWII was over, and Japan and Germany’s industrial base needed to be rebuilt, the US sent Operations Research experts over to teach and train. This basis in statistics and systems analytics eventually helped birth the Toyota Production System and Lean Manufacturing in general including Deming’s statistical Six Sigma methods. And not to simplify too much, but this entire history is just a cacophony of information transfer, growth, and development ultimately merging back today in Lean Six Sigma. From here we can pull another interesting thread in that the Software Engineering discipline of DevOps is rooted in Lean Six Sigma as the book The Phoenix Project enjoyably novelizes.

Industrial Engineering was also birthed from OR and remains the only undergraduate discipline where OR principles are introduced. The point is that these disciplines emerged from statistics and OR and were specialized to apply across other disciplines in ways that ebbed, flowed, morphed, merged, and emerged across the industries under a large number of separate titles.
What does this have to do with Data Science? Because they are rooted in the same foundation as all the others we just discussed. Statisticians, heavily rooted in OR and trying to overcome the adage, Lies, Damned Lies, and Statistics, took the opportunity in the 1990s to re-label statistics into Data Science. The success of this branding was impressive as Data Science exploded in the mid-2000s and is still one of the fastest-growing disciplines on the planet. But in this success, they forgot where they came from and, in doing so, they forgot two important things from their history.
What Data Science Forgot

As this LinkedIn post so appropriately captures, The main thing Data Science forgot is that understanding the data and the goals for the data are essential. In doing so, they fundamentally forgot their roots when it comes to Operations Research and Statistics which have a fundamental rule each:
Operations Research - Answering the why before the what or how.
Statistics - Form a null hypothesis and then work to disprove it.
Forgetting to validate and tie to actual business objectives and forgetting that you aren’t supposed to prove the hypothesis but disprove it, is exactly what the xkcd comic above demonstrates and something that has driven me nuts for years.
All too often when a Data Scientist arrives, they inevitably say “give me your data, and I’ll derive answers.” My first inclination is to respond “No shit.” You’ll always find patterns in data. The key isn’t the data, or the patterns but the question you want to ask of the data. But even that is a risk because tortured data, like humans, will always give up an answer. And that answer is rarely correct.
Then, adding insult to injury, they apply algorithms and clean the data in ways that virtually guarantee the answer they are hypothesizing. They’ll apply everything possible to justify an answer which is causing a huge problem with replicability and reproducibility of studies as well as challenges with explainability in Artificial Intelligence and Machine Learning. In the end, it results in perpetually doing analytics, rarely providing true valuable insights, and failing the customers of these models.
Proposed Solutions
The first solution goes back to remembering and analyzing your history. Getting back to the basics of analysis, making sure you are answering the right question, with the right data, with the right tools. It doesn’t matter if you are OR, Lean Six Sigma, Industrial Engineering, a Statistician, or a Data Scientist. Tools are just tools until the context, and the hypothesis testing is done right.
Solving the business goals problem requires applying the Polymathic Mindset and keeping your head up and looking across disciplines to find the commonalities, leverage the strengths in each, and pull together a better solution than any one of them can on their own. This helps to ascertain the goals, their interrelationships, and whether they need to be adapted to new expectations or conditions.
Operations Research addresses this problem through a series of layered metrics:
Measures of Outcome (MOO) - The most qualified and initial starting point, these measures look to the longer-term goals that could be phrased like “win the war”, “maintain 45% market share”, or “increase compound annual growth rate (CAGR) by 50%” (this last one could also fall into the category of a MOE.
Measures of Effectiveness (MOE) - At the next level of fidelity and in the balance between qualified and quantified, this level looks to answer whether we are doing the right things to achieve the outcome. It helps to focus the efforts on priority tasks vs. nice to have. If it isn’t improving effectiveness it probably shouldn’t be tracked.
Measures of Performance (MOP) - This is the third level and focuses on whether we are doing things right and is naturally quantifiable and should address an acceptable range(s) of performance measures. MOPs are generally at the level that we’d consider official requirements in Systems Engineering. Important to note, in relation to requirements engineering, is that to be appropriate requirements, they need to be tied into MOEs and MOOs!
All too often, if requirements are even formalized, they are not tied into the less quantified precursors and so lose focus on the actual outcome desired. The proverbial “missing the forest for the trees.” Yes, we need to get into the practical application but keyword “Practical” vs. just application. This last part is also a key failure in many development programs and proofs of concept in that there is so much drive to Do Something that we rarely pause and ask why.
Once we understand the question, the second solution is one of the most important: Work to disprove your hypothesis. The bastardization of science through p-hacking and other statistical tricks evolved to prove the hypothesis correct. Call it a function of the “publish or perish” mindset in academia, but it still drove a behavior away from the cornerstone of analytics and gives credibility and acceptance to questionable analytic processes. This allows the character in the xkcd comic to just ‘stir the pile’ until the answers come out. But that’s not science and therefore, we can’t call it Data Science at all.
To remedy this behavior, it helps to learn just how wrong, and at what consequence, we’ve been in the past. A great book on the topic is How Not to Be Wrong: The Power of Mathematical Thinking. This book ties together a few of the previous topics and provides a lot of great examples, like the bullet holes in bombers, and other classic mathematical correlation blunders, and reinforces the thesis of this essay. It helps to see how wrong we’ve been and how much that has affected public policy and opinion to see how important it is to get it right!

The final solution is to address our data and this is where it gets a lot more challenging because, as I explored in Eliminating Bias in AI/ML, the data layer is often a mess. Between poor data architecture, governance, and cleanliness, there is a huge risk in running any algorithm on the data and being able to trust the results. We need to be very diligent in designing data systems for holistic, not ad hoc analysis, and with architectures that are composable and scalable, not fractured and siloed.
Furthermore, we need to recognize that historic data only tells you how you’ve operated to date. It does not tell you how you should, or could, operate in the future. Frankly, we need to remember the classic investment rule: “past performance is no guarantee of future results.” While understanding history is important, and illuminating unrecognized patterns in past performance is useful, Data Scientists should spend more time helping businesses analyze where they’d like to go, rather than trying to predict the future on dirty, historic data.
Conclusion
Understanding our roots, ensuring we are asking the right questions, tied to business goals and good requirements, and then working to disprove our hypotheses will help Data Scientists in adding true value to the world instead of torturing data for answers. This isn’t limited to Data Scientists either. All disciplines benefit from an understanding of these concepts from the Business Manager to the Software and Data Engineers, to the layperson reading the latest ‘study’ results and wondering what it means for them.
What I’ve loved the most about Operations Research is, that given the role to continuously drive for optimization, I’ve learned to tie analysis to objectives, what sort of tools and qualified vs. quantified analysis to use based on the data, and when to reject the hypothesis even if it is a favored idea because doing otherwise would compromise the analysis. Lastly, it’s also about bringing in all the related disciplines from OR to Industrial Engineering, to Lean Six Sigma to Data Science, into a polymathic network that really helps to bring our analysis to the next level.
Enjoyed this post? Hit the ❤️ button above or below because it helps more people discover Substacks like this one and that’s a great thing. Also please share here or in your network to help us grow.
Polymathic Being is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
This accounts for my ongoing skepticism of fully autonomous unpiloted automobiles in unpredictable highway conditions. Speaking as someone with over a million miles of professional driving and no accidents in the era before any automation, I'm a fan of computer assisted driving, but mystified by the emphasis on achieving the last 10% (or so) required to entirely replace a human driver. Most freight handling and most auto passenger service jobs require a significant component of presence from a human--traditionally involving the human vehicle driver.** They might as well handle that crucial last 10%. Occasionally on the great highway, drivers and navigators encounter anomalous phenomena, presenting the sort of problems for which a computer lacks proper context, and could never learn on the fly.
Anyway, my suspicion about the techies working so intensively and expensively on making a fully remotely programmed vehicle is that they never did the job. Or, anyway, enough of the job to really have a grasp of it. Speaking of what Greg Wagner mentioned in that LinkedIn note quoted in the post.
I sometimes indulge a suspicion that the people most invested in the AUV project think it's of utmost importance because they hate to drive: they're aggravated and frustrated by the experience, view humans as accident-prone (although we're also accident preventable, with some forethought), and don't drive very well themselves, especially in traffic. So they're committed to replacing all that messy human quasi-parallel processing with the One True Ideal Algorithm to rule it all.
[ *more difficult to acquire with an auto navigating urban-suburban-rural streets than with OTR trucking. ]
[**theoretically, robots. Thereby inducing an extra level of Fragility. Robot get sick, no two aspirin work.]
Great post I just read, on the relationship between complexity and fragility: https://karlastarr.substack.com/p/welcome-to-peak-complexity-why-modern
And the Manhattan Project ignored by all data scientists and managers: develop a means and effective metric[s] that measures the quality and veracity of all data going into and coming out of the systems. Not a matching relationship check but a genuine means to measure the truth, provenance and "meaningfulness" of data and aggregated pools of it.